Tracking down quality defects, quickly and precisely. Analyzing defects right on the component and tracing root causes across manufacturing steps is key for consistent quality assurance and stable manufacturing processes.
THE ADVANTAGES AT A GLANCE
Faster Process Understanding:
Adjustments and effects on component quality immediately visible
Fewer quality defects:
Efficient tracing & elimination of recurring defects
More process stability:
Automatic detection of defect patterns and machine drift
WHAT’S IT ABOUT
Quality analyses made easy
In order to avoid production rejects permanently, it is fundamental to build up a deep understanding of the manufacturing process and to trace quality defects back to their origin. However, especially in complex and newer manufacturing processes, it is often not clear which machine settings influence each other and which process parameters from one manufacturing step may affect the next manufacturing step.
The more complex a process, the higher its need for transparency
The Quality Analyses application simplifies such examinations and makes it possible to determine the root causes of defects in just a few clicks: data on each component is automatically displayed to the user as a digital twin in false colors. By applying functions such as a hotspot filter or a histogram, the user can specifically search for outliers or defects patterns in the data and locate them in the component.
The overlay of the CAD model helps with orientation. In addition, several components can be compared with each other and the largest process differences automatically displayed. Finally, data from different process steps (e.g. manufacturing data and data from non-destructive testing) can be correlated to identify correlations.
Applicability and benefits across manufacturing departments
The analysis options are extremely diverse and fast. The user benefits from a steeper learning curve not only in pre-development phases but also in ongoing production, he ensures manufacturing quality faster and avoids production scrap.
MAIN FUNCTIONS
Point selection & cube resolution
When selecting individual data cubes, information about the range of values, position and number of data contained is displayed. The resolution can be adjusted so that more or less data is combined in one cube.
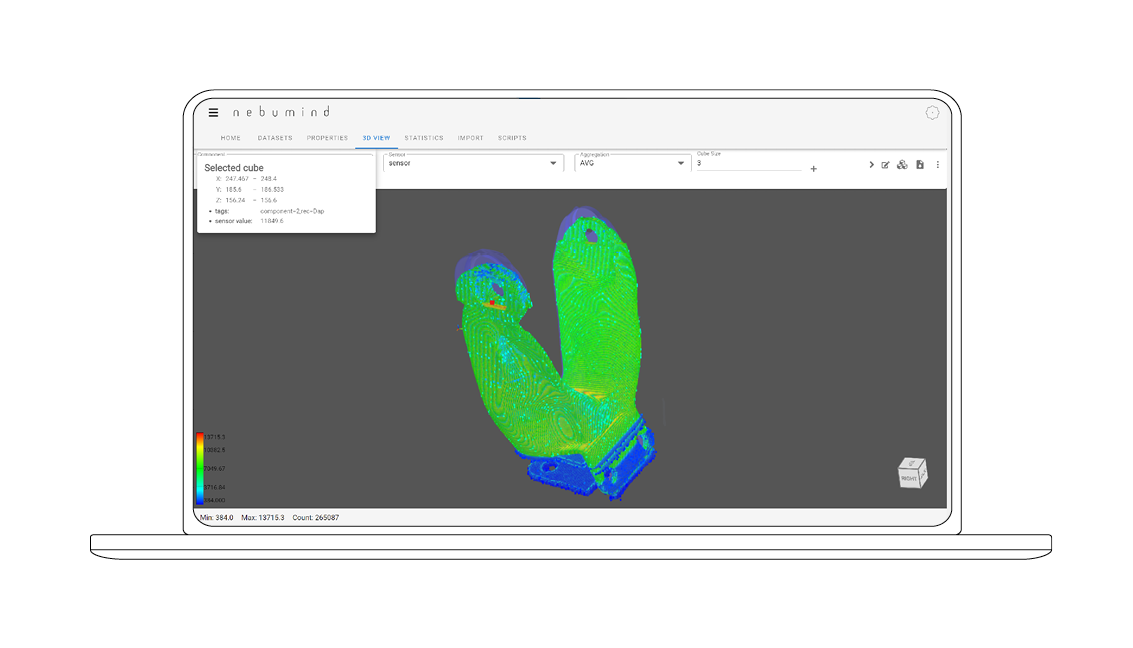
Data filter
Data cubes can be filtered by value ranges or location ranges, so that, for example, only the highest or lowest values are displayed, or only data in a certain area of the component. The overlay of the CAD model helps to orientate in the construction space.
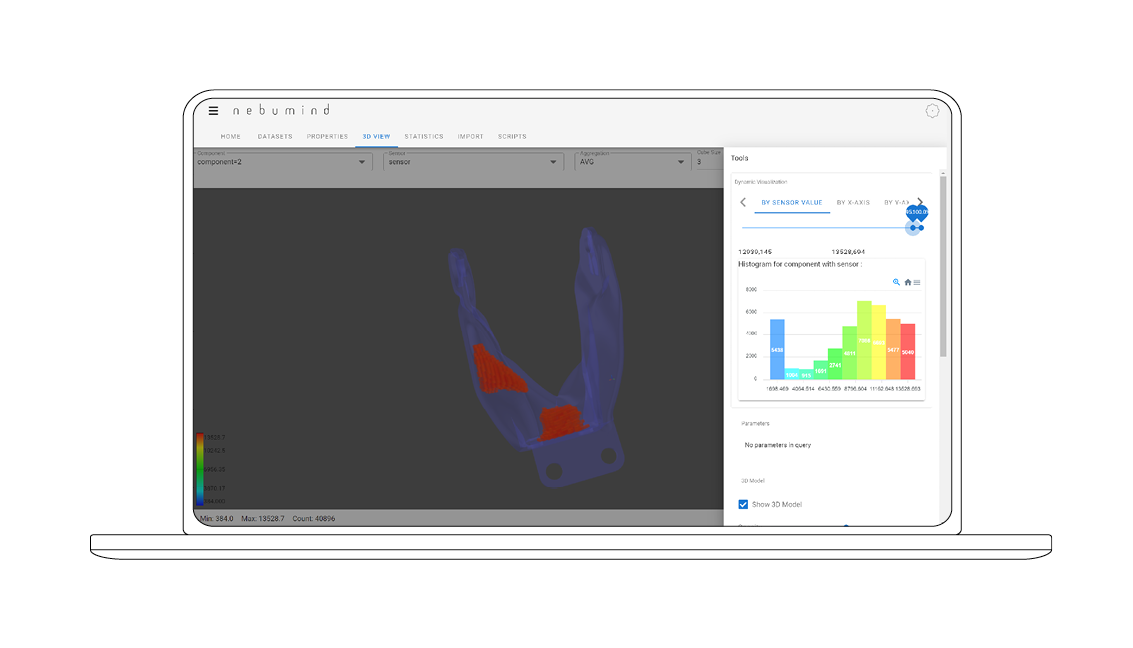
Region of interest
Areas or cubes that are of particular interest and require closer examination can be marked and selected by clicking on them. The data in this area will then be displayed in high resolution.
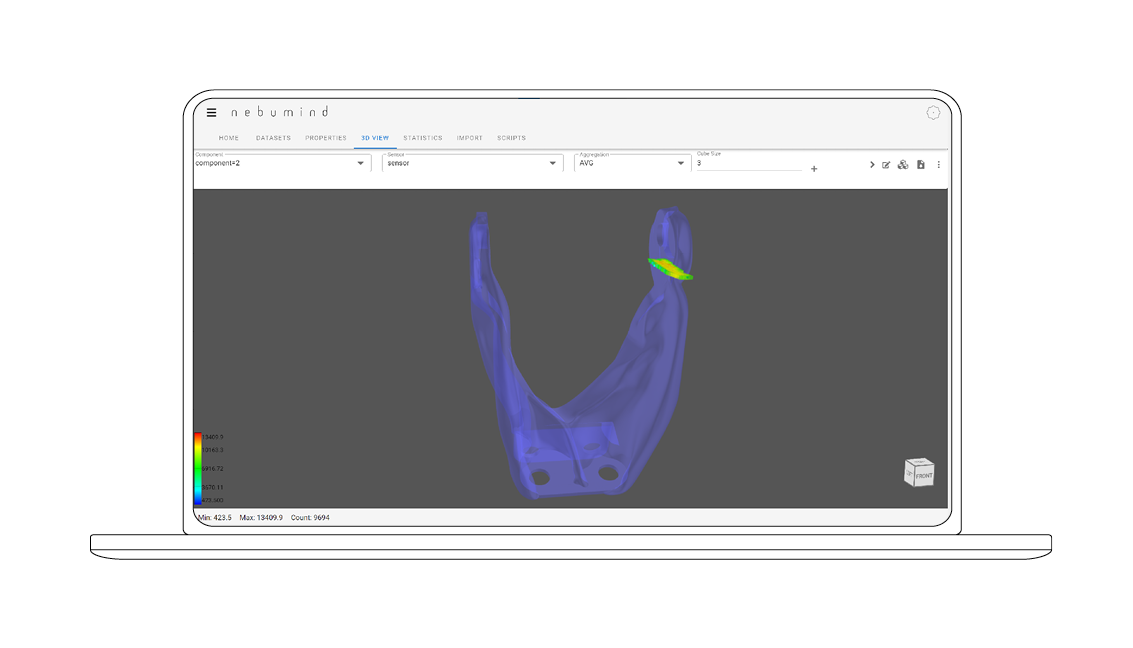
Query & analysis storage
While the main functions are available as click features, a query is freely available for more in-depth or more individual analyses. Important analyses and results can be saved directly for later follow-up or for sharing with colleagues.
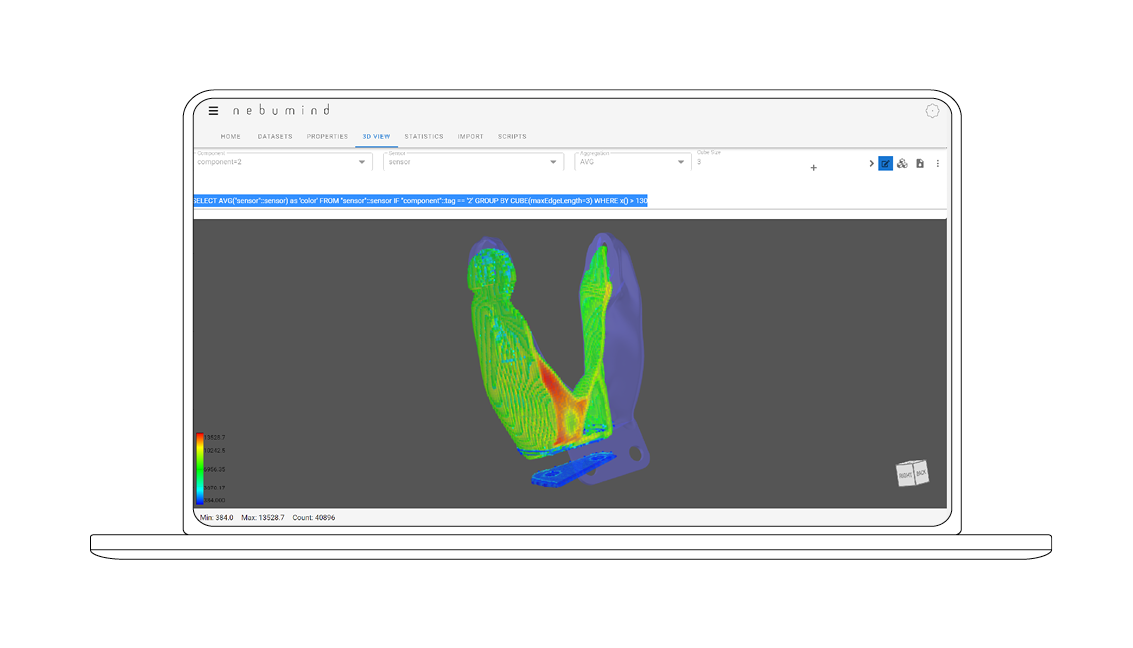
Build-up of digital twin
Data can be displayed in chronological order, just as it was generated and recorded on the shop floor during manufacturing.
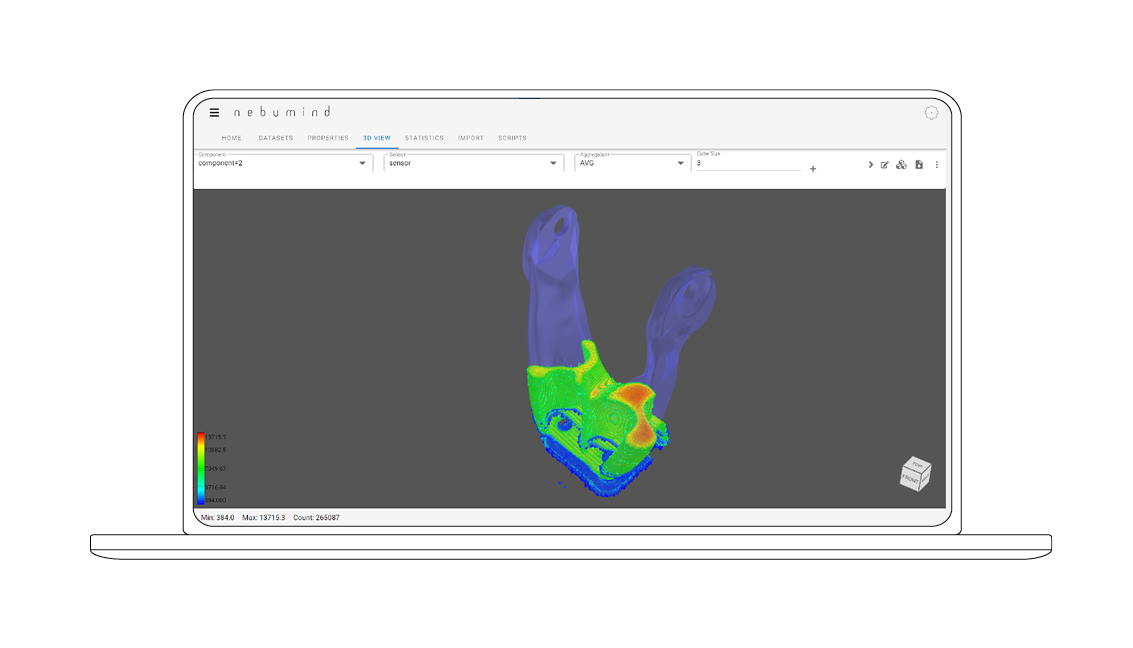
Twin comparison
Different components or even data from different process steps for a particular component can be compared with each other, manually or automatically, by subtracting their digital twins from each other. Manufacturing differences can be examined in the form of a „difference twin“.
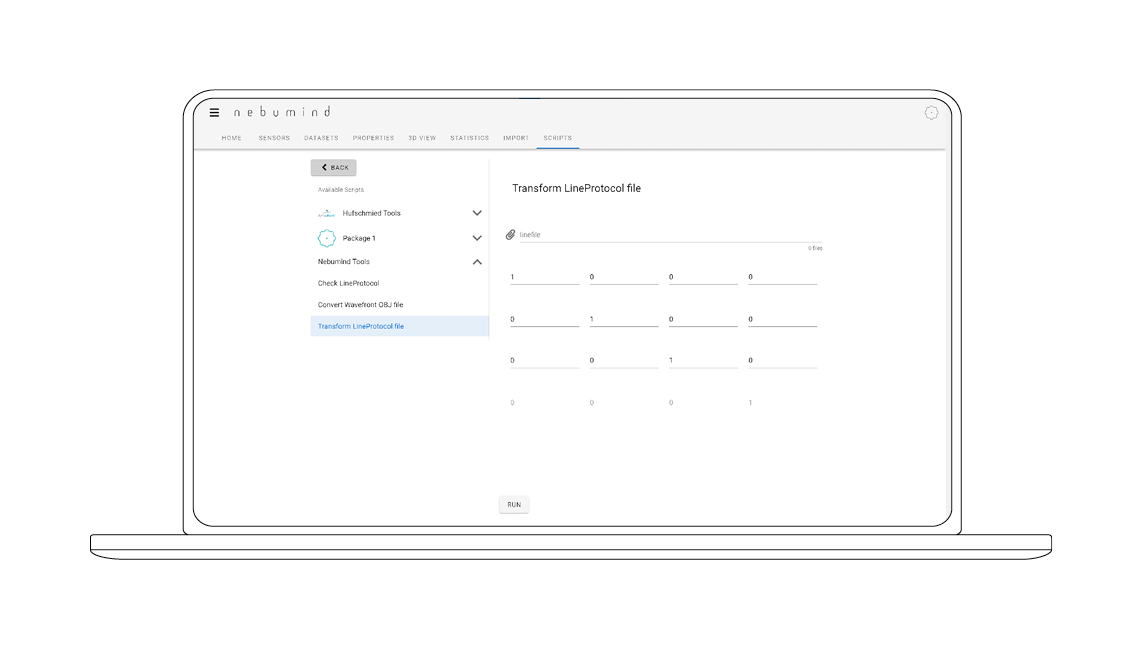
Loading individual scripts / AI algorithms
Self-created Python scripts can be loaded to perform highly specialized, custom analyses or to create custom plots (e.g. with Matplotlib, Plotly, etc.).
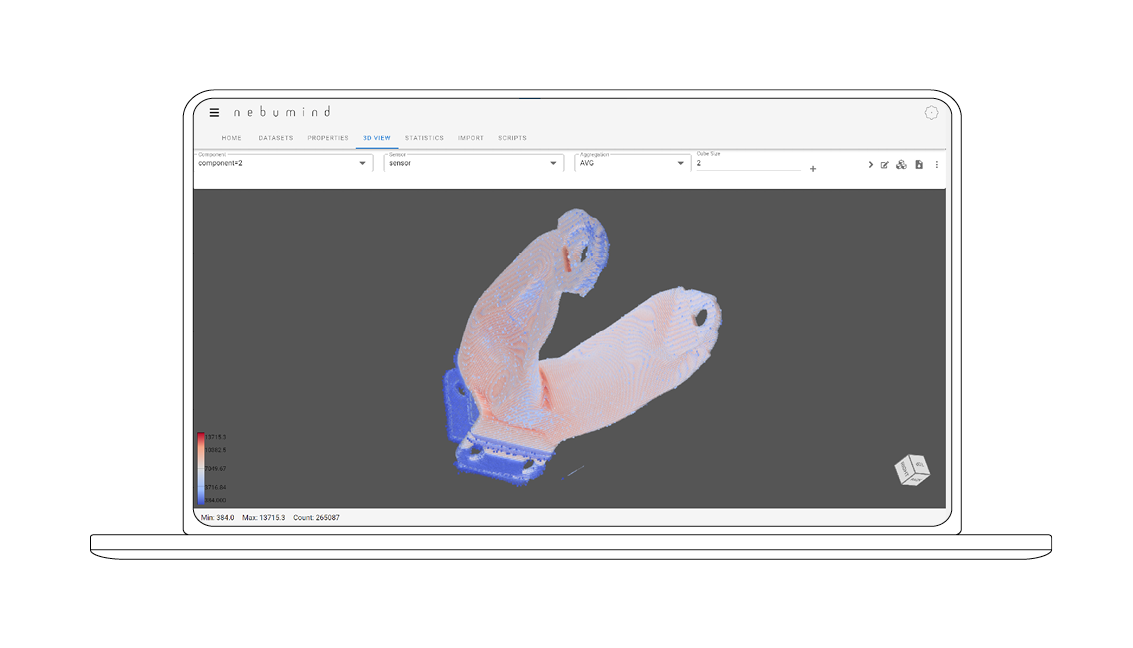
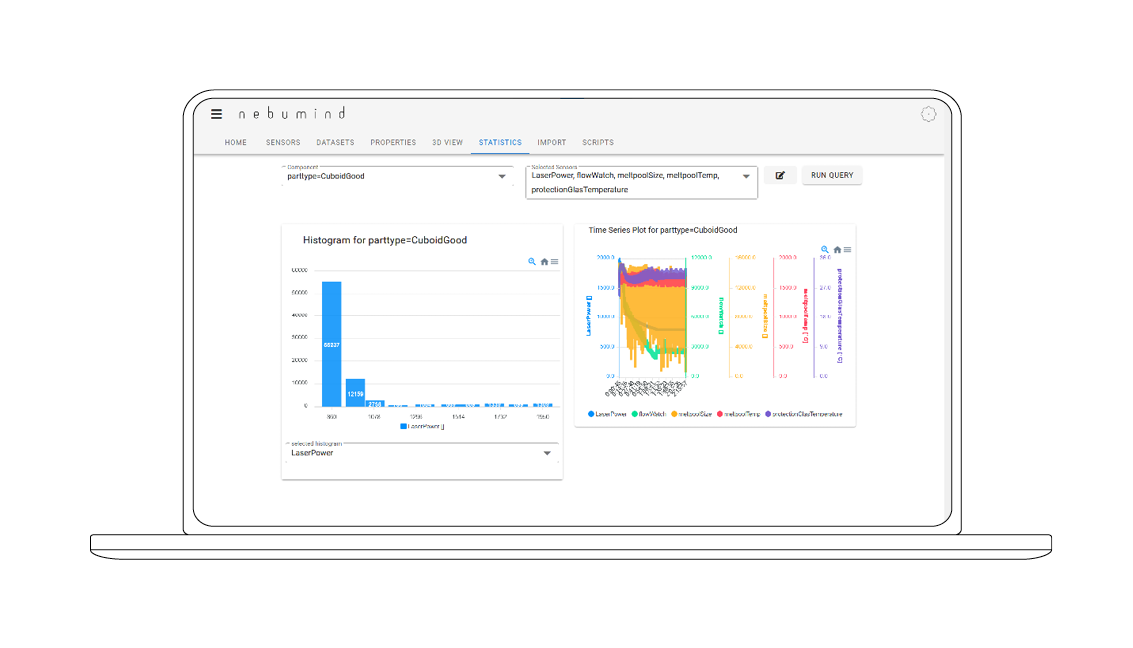
Value distribution, time graphs, correlations
The values and their distribution within a component can be analyzed with different plots (e.g. histograms, correlation plots, scatter plots). Time series analyses are also possible. For correlation analyses, different data sets are displayed in a scatter plot.
Machine analyses
By using various metrics applied to historical data, correlations between decline in component quality and decline in machine condition can be investigated.