Organizing data more efficiently. Data of all process steps is collected, structured and stored for every component automatically. This not only saves the time to manually clean and merge data into a common format, but also makes data accessible long-term.
THE ADVANTAGES AT A GLANCE
80% time savings:
automatic data collection
and preparation
Full transparency:
Data can be retrieved at any time and from anywhere
Long-term data storage:
Data stored in a highly structured way for fast and long-term searchability
WHAT’S IT ABOUT
Data Management made easy
The goal of the Data Management application is to quickly provide all production data recorded for individual components on the shop floor and store it for the long term. Today, productions in data analytics projects spend most of the time (80%*) on data collection and preparation before actual analyses can be performed. Data is available on different computers, in different formats and of varying quality, and must first be merged and structured.
Data management needs to become more efficient
The Data Management application replaces this considerable manual effort: data from sensors, machines and third-party systems is automatically collected, harmonized and prepared in a user-friendly manner, and presented in a central overview for each component. The overview provides, for example, information regarding component number, component type, machine type and recorded process parameters.
* American Society of Quality (ASQ), 2020
The user can filter for specific information or start his analyses immediately by means of the digital component twins. In a personal area, he can save specific data sets and performed analyses or share them with colleagues.
Long-term storage & foundation for AI algorithms
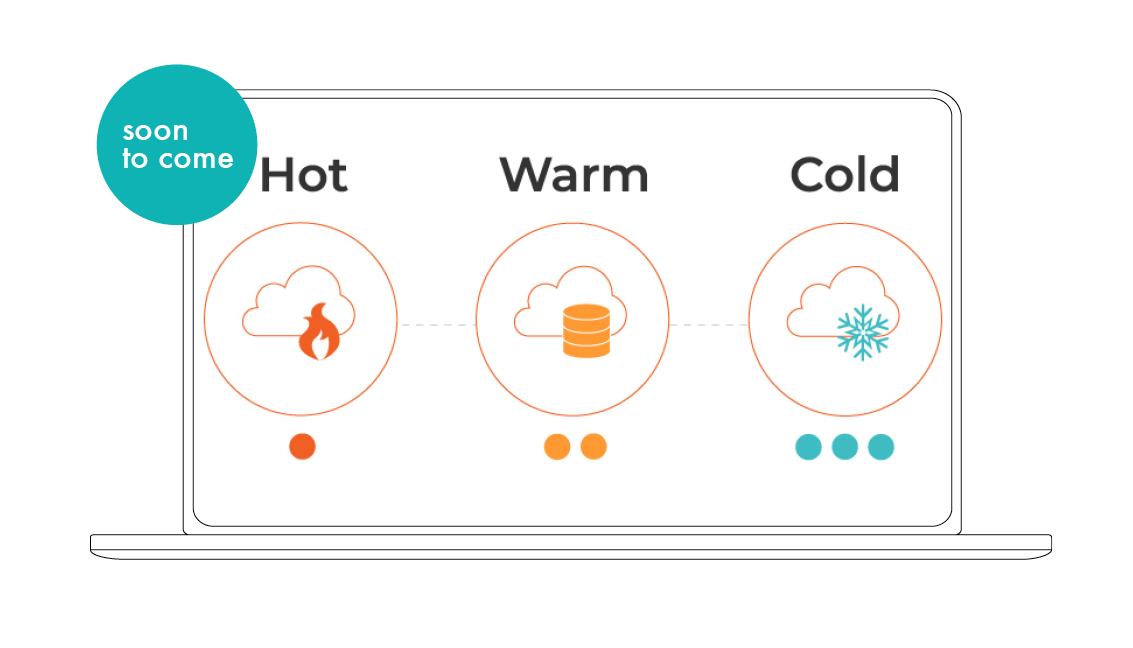
The data is stored long-term according to the hot/cold data principle to reduce storage space and can be reloaded automatically. Particularly in case of recall actions, the time required to compile information on a component and to locate components with similar risks is reduced significantly. Finally, the efficient and highly structured data preparation also provides a perfect base for AI algorithms that can immediately access the data in the nebumind software via different interfaces.
MAIN FUNCTIONS
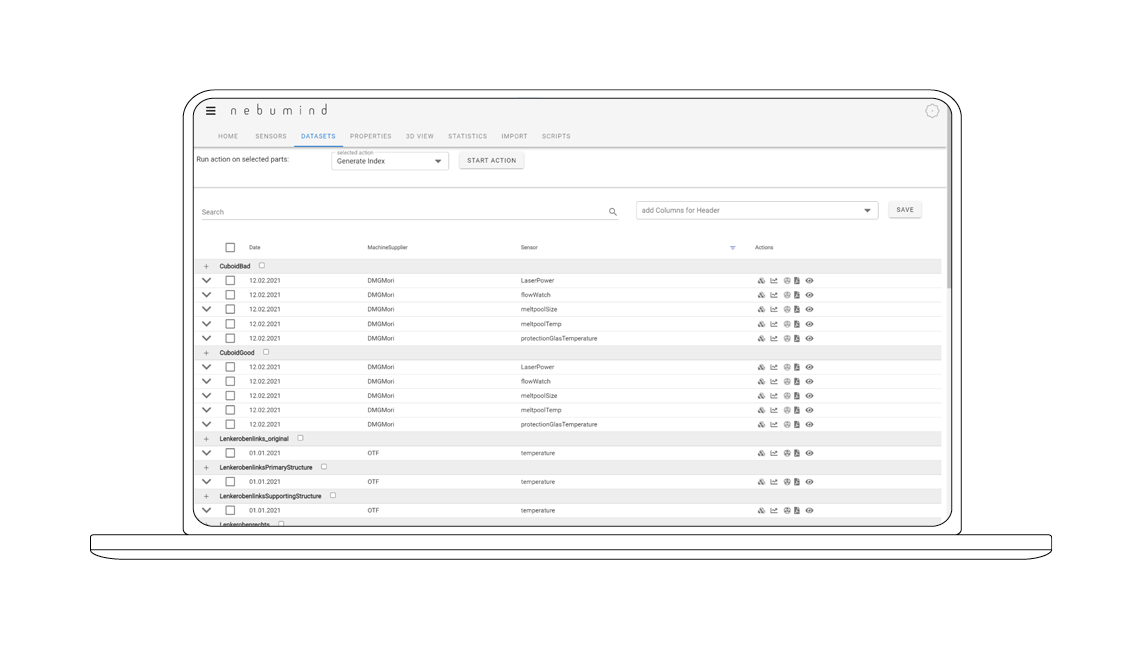
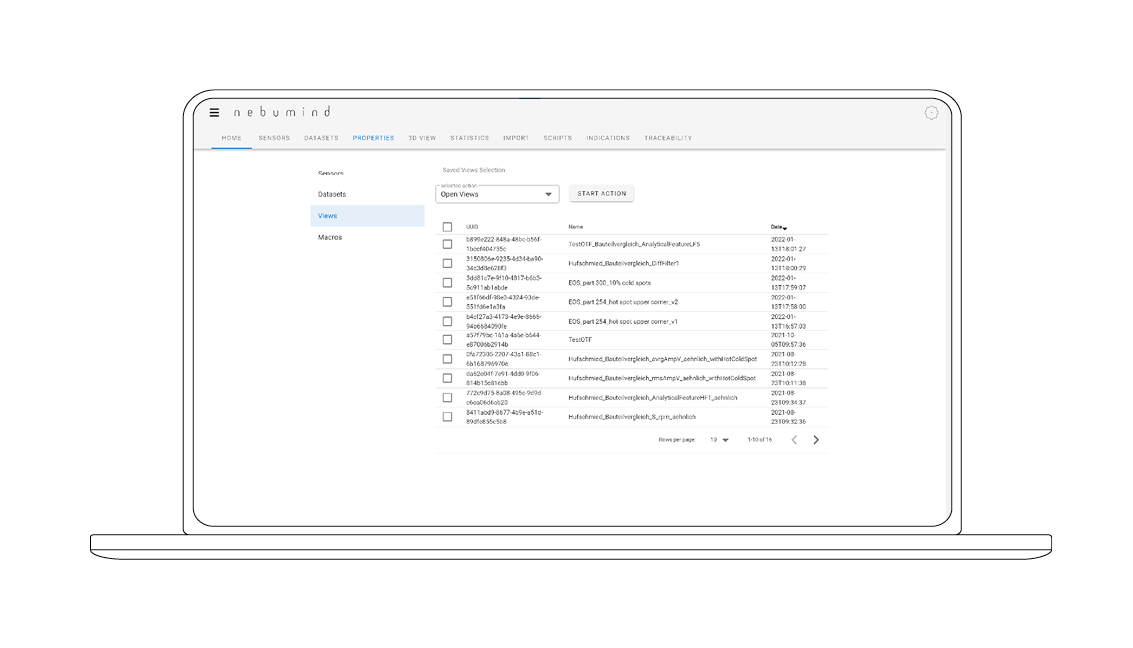
Overview of all data sets
All data sets recorded by machines, sensors and third-party systems are managed in an overview. These can be filtered and searched with just a few clicks. Additional information, such as meta data, can also be added or completed later on.
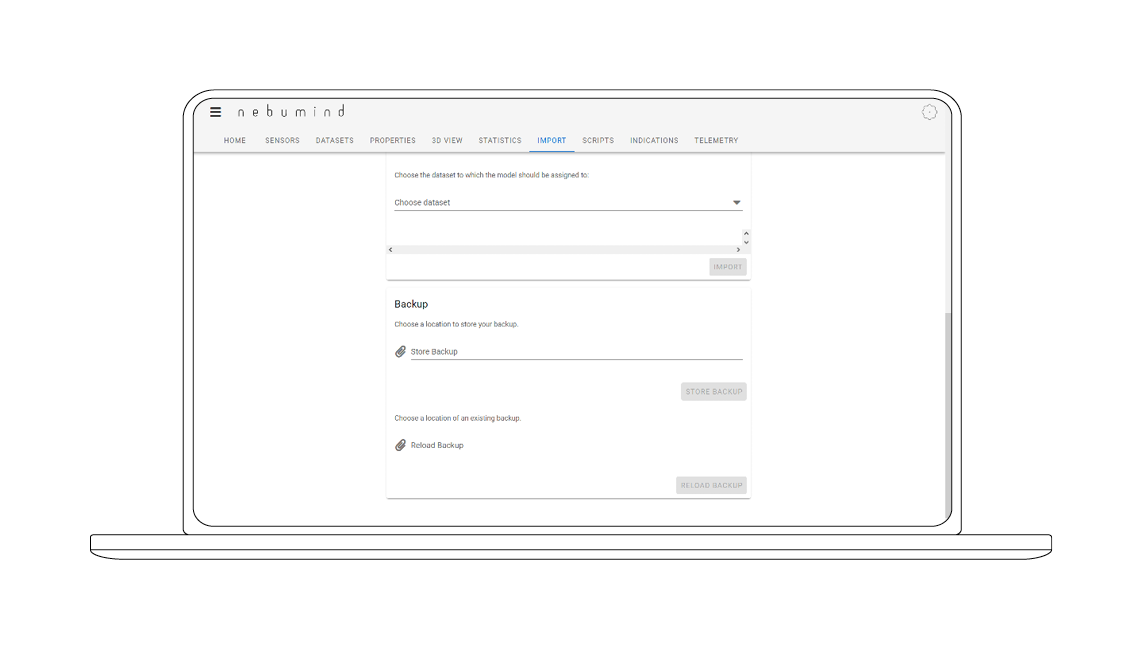
Long-term storage & back-ups
The permanent storage of data for each component enables production information to be retrieved quickly and easily, for example in the event of product recalls. In addition, automatic back-ups are performed, the regularity of which can be configured by the user.
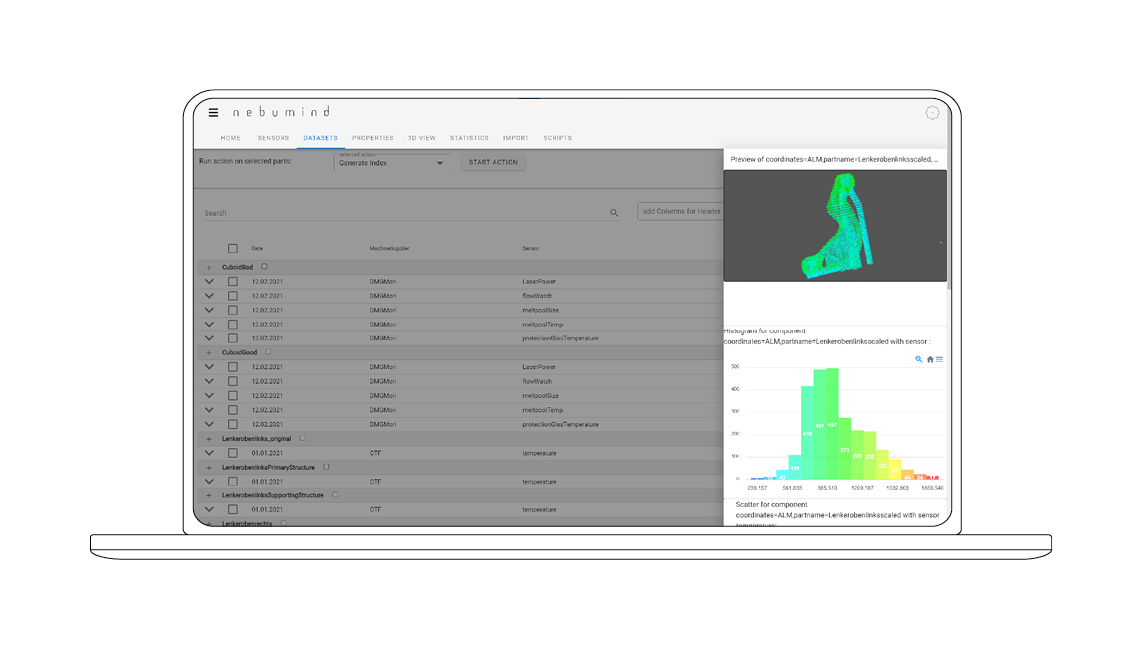
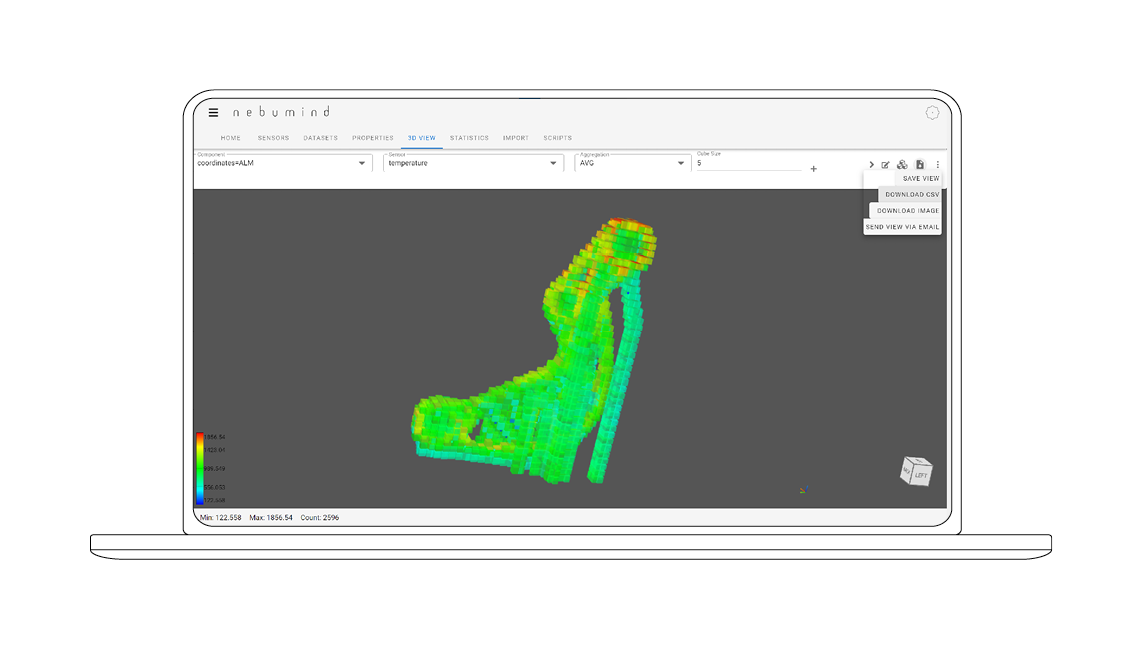
Preview data analytics
A preview shows a first 3D visualization and statistical analysis for each data set.
Personalized area
Dashboards with saved analyses, scripts and data sets can be created.
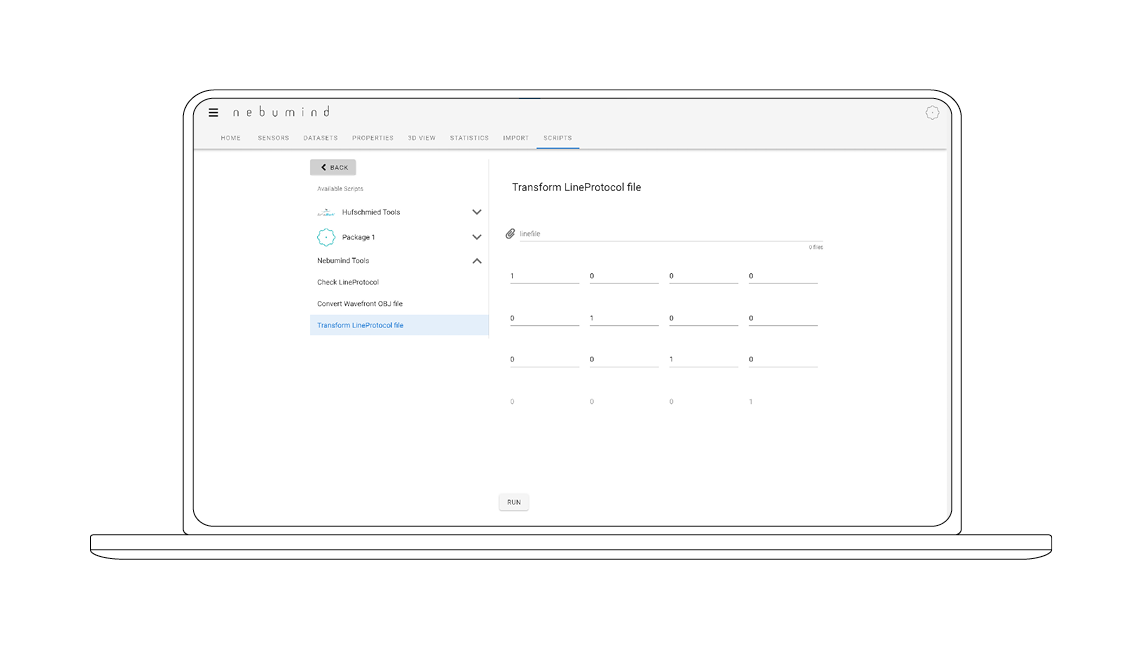
Loading custom scripts / AI algorithms
Self-created scripts and algorithms can be loaded to read custom data formats and pre-process data before saving, if necessary.
Arbitrary export
The software is compatible with other systems and can export data to special formats such as point clouds, csv, json and xml or stream it via MQTT or OPC-UA. Other systems can query and use data from the nebumind software via a web interface (REST API).
Compression of data
Huge amounts of data can quickly become expensive. Therefore, nebumind allows for compression of „old“ data according to the „Hot vs. Cold Data“ principle and automated decompression if the data is needed. The data size can thus be kept low and costs can be saved without compromising analysis performance.